Process API Changes in 6.0
Carbon Black EDR (Endpoint Detection and Response) is the new name for the product formerly called CB Response.
EDR 6.1 brings many fundamental changes in the Process API to improve performance, scalability, and also add features to the product. This page will describe all of the additions to the Process API and how they will affect your use of the EDR process API endpoints.
New Document Model
One of the most notable features in EDR is its concept of “Process Documents”. EDR needs a way to keep all information about a process that ran on an endpoint together in one place - this is known as the “process document”.
The biggest change in EDR 6.1 is how these process documents are stored. In previous versions of EDR, the server would aggregate all events associated with a given process into one “process document”. This document contained several key data points: metadata about the process itself (username, hostname, command line, etc.), information about any threat intelligence hits from Watchlists or Feeds, and a listing of all events (regmod, filemod, netconn, etc) that were associated with the process.
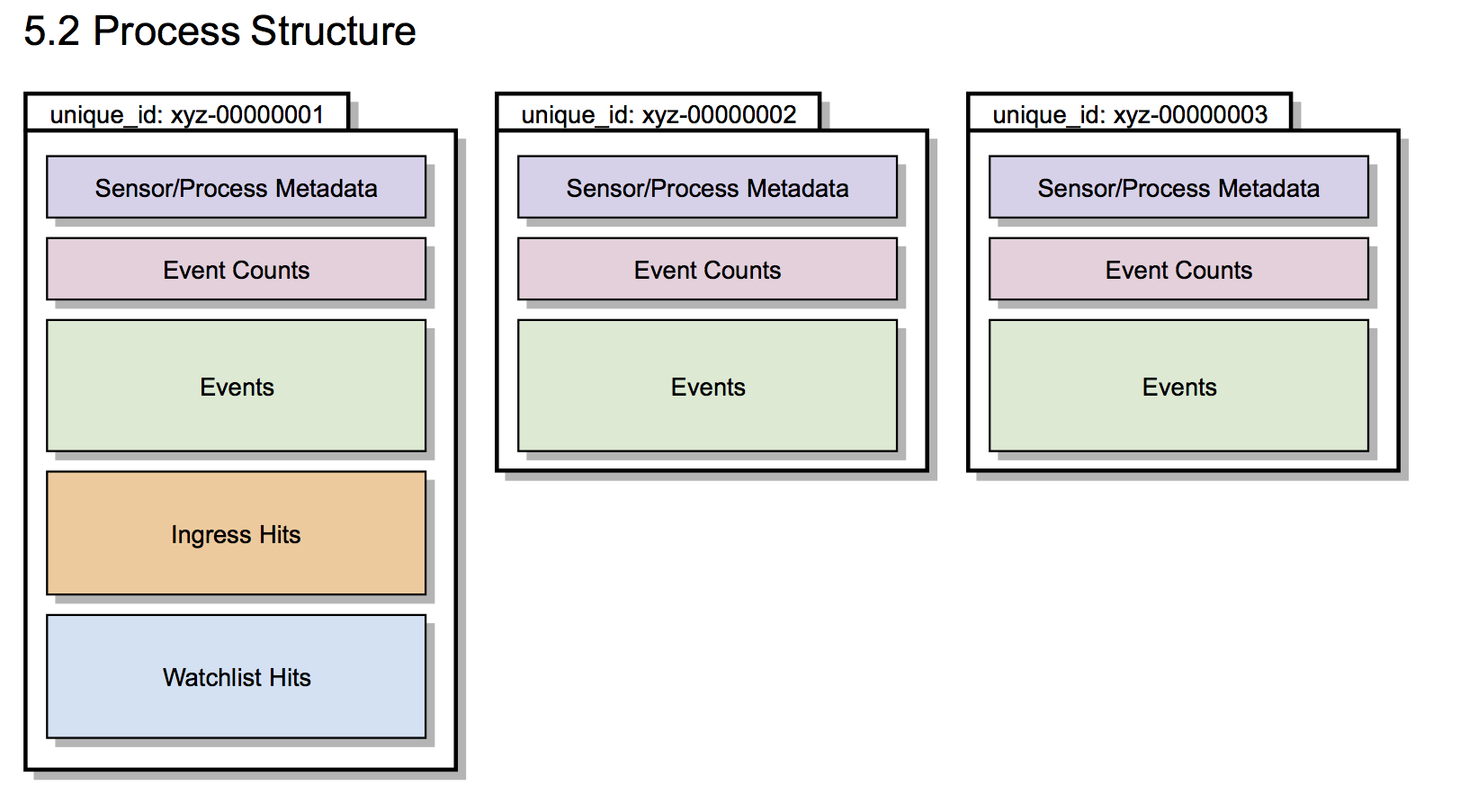
How Documents Used to be Stored
In earlier versions of EDR, the process document was overwritten as new events were received by the server. When a sensor checked in with the server, it would retrieve the already-stored documents associated with every running process on the system, append the events from the checkin, and save the updated version of each process document.
The only exception to this “one document, one process” rule was when EDR encountered long-running processes with many thousands of events. Since the process of retrieving, rewriting, and re-inserting very large documents was an expensive operation, processes with more than 10,000 events were split into multiple process “segments”. The segments were numbered consecutively, starting with “1”. When over 10,000 events were recorded cumulatively (across all event types) for a process, a new segment “2” was started, and so forth.
Most processes in 5.2 consisted of only a single segment and long running processes were the exception rather than the rule. Most users did not encounter processes with a segment ID of anything other than “1”.
The previous (< 6.0) behavior can be seen by the diagram below:
New Immutable Model
EDR 6.1 dramatically changes that model. In this new model, process documents are “immutable” - that is, as new events are received, new segments are created and the existing segments are kept unchanged. Therefore, even a short lived process may be represented by several process segments in EDR 6.1.
See the diagram below for an overview of how this looks in EDR 6.1.
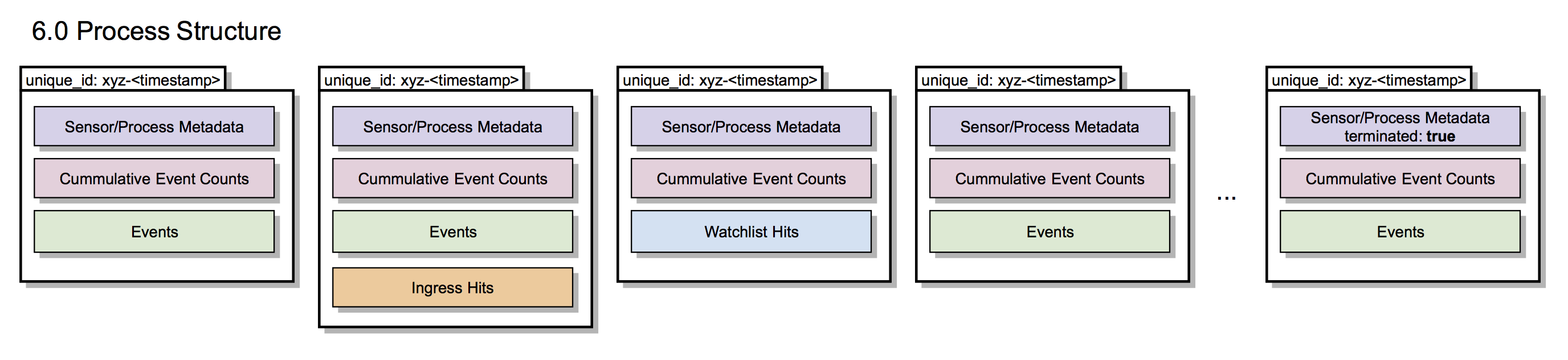
EDR 6.1 now numbers the process segments by the timestamp that they’re inserted into the database rather than sequentially. Therefore, the process unique_id format will change slightly - last part of the uuid will now be 12 instead of 8 digits, and will be in a hexadecimal instead of decimal number. This part signifies the segment of the document and will now be a timestamp when segment was received from the sensor (except for a very first segment, which will be 1, but only in case of legacy 5.x sensor). Example: 00000001-0000-0000-01d1-ac4d9bee85ab-000000000001, 00000001-0000-0000-01d1-ac4d9bee85ab-0123A6CFE873
Segment of the process (segment_id) field matches segment part of the unique_id (timestamp for all segments except for the first segment for 5.x sensors)
NOTE: The segment id is in decimal, not in hex when part of the uuid.
EDR 6.1 will keep track of the last segment (segment where process termination was observed). This segment is identified with the field terminated set to true. There is no indication for the “first” segment in the general case, however, remember that all segments include the process metadata common to each segment.
Event Partitions
Previous versions of EDR held all process documents in one central database, or “core”. EDR 6.1 now shards process documents across multiple database “cores” or “partitions”. This improves both performance and data retention. By sharing data across multiple time-based cores, you can hold historical data in “cold” storage (where it’s not available for immediate search, but can be re-imported as necessary) while keeping recent data in “warm” or “hot” storage (where it can be immediately searched via the API and UI).
Partitions can be:
- Hot: There is always exactly one hot partition. It is called “writer” (configurable). All new data goes to the writer partition. Hot partition can be searched. By default, a new “hot” partition is created every three days. Once a new “hot” partition is created, the previous “hot” partition is moved into “warm”.
- Warm: Warm partition is any mounted partition that is not currently written to. Warm partitions can be searched. Warm partition are named as “cbevents_<timestamp>” where timestamp is time when partition was created in format “YYYY_MM_DD_hhmm”. Timestamp can be followed by suffix in format “_<suffix>” which will be ignored and can be used to specify additional partition information. Here are examples of valid partition names:
cbevents_2016_06_11_1351
cbevents_2016_06_11_1351_foo
cbevents_2016_06_11_1351_this_is_partition_from_old_server
- Cold: Cold partition is any partition that is not mounted to Solr, but exists only on disk. Cold partitions can not be searched, but can be mounted (converted into warm partitions) Deleted: Deleted partition is removed from disk and can no longer be looked up or restored
More info on the APIs to manage partitions can be found on the REST API.
Upgrading from 5.x to 6.x
Clearly, these changes represent a large shift in how data is represented in the EDR backend. Migrating existing 5.x events into the new schema would be very inefficient, so the upgrade process simply moves the existing 5.x data into its own warm “partition” (see the “Event Partitions” section above) and starts a new “hot” partition in the new 6.x schema. Once 30 days has past, this legacy data partition is moved to “cold” status.
Since the legacy data partition and the new 6.x data partitions are using different data schema – most notably, the primary key has changed type from integer to string – special care must be taken when attempting to search for process event data across both cores.
Process REST API Changes in 6.x
With the conceptual model out of the way, let’s talk about how this affects the use of the APIs when searching for process matches.
Searching the process store is still performed via the /api/v1/process endpoint, either using the GET or POST HTTP verb. However, there are some additional
New Query Parameter: cb.legacy_5x_mode
This parameter should be set to false for all searches in 6.x. The cbapi Python module automatically sets this query parameter to false.
Process Joining (“comprehensive” search)
Since process “segments” in pre-6.0 servers were so large (10,000 events by default), most searches could ignore the fact that events could be split across multiple process segments. However, in 6.0, the process segments are very small and could contain as little as a few dozen events per segment. Therefore, more complex boolean queries or queries that contain the “not” operator cannot operate on individual process event segments alone for accurate results.
This is easier to illustrate by example. If you attempt to search for domain:microsoft.com AND domain:yahoo.com, but the network connections are stored in two different segments like so:
Process ID 00000001-0000-0000-01d1-ac4d9bee85ab, segment 1024:
process_name: chrome.exe
netconn events:
outgoing -> google.com 443
outgoing -> 1.2.3.4 80
Process ID 00000001-0000-0000-01d1-ac4d9bee85ab, segment 2048:
process_name: chrome.exe
netconn events:
outgoing -> 2.3.4.5 443
outgoing -> yahoo.com 80
If we search for processes that contacted both microsoft.com and yahoo.com, you can see that no one segment contains both network connection events. However, the same process did contact both domains; it just so happens that those events are spread across two different segments.
Therefore, EDR 6.1 invokes a “comprehensive” search whenever a boolean query involving “and” or “not” operations are executed. EDR 6.1 will automatically “join” together the individual segments to evaluate the boolean query across the entire process, not just the individual segments. The result set will include all of the segments of a process if the search matches the event set.
Note that this automatic “comprehensive” search has two known issues:
- Comprehensive search does not function across data partition boundaries. If, for example, the two events involved in an “and” query span over a four day span of the same process, they will not be combined in the join and the query will not match that process.
- Comprehensive search cannot join across events in a “legacy” (pre-6.x) core. The original search semantics (per-segment) apply to events in a data partition that was created with EDR 5.2 or earlier.
Search time windows
Now you can search for events in time windows. This helps performance as we can avoid searching entire Solr cores that contain events that fall outside of the time window you’re selecting.
You specify search windows through four new query parameters on the Process search endpoint (/api/v1/process):
cb.min_last_update: Minimum last_update timestamp (relative to sensor) found for the processcb.max_last_update: Maximum last_update timestamp (relative to sensor) found for the processcb.min_last_server_update: Minimum last_server_update timestamp found for the processcb.max_last_server_update: Maximum last_server_update timestamp found for the process
For each field, the date/time is always in UTC and the format (compressed ISO 8601 UTC) is: 2017-04-29T04:21:18Z
Process Details
There is now a new API endpoint, /api/v2/process/<guid>/<segment>, available for retrieving the process metadata associated with a given process/segment combination. This API endpoint only returns the metadata associated with the process GUID & segment, and does not include information on the sibling (parent/children) processes.
IPv6 Support
A new process event endpoint (/api/v4/process/<guid>/<segment>/event) was added in EDR 6.1 to accurately report back IPv6 addresses to callers in the API. Now, the netconn_complete field contains strings instead of integers for all IP addresses, ensuring compatibility with both IPv4 and IPv6 addresses.
Last modified on May 5, 2020